打游戏时领悟了“向死而生”,这个AI算法真的不虚强化学习
编者按:本文来自微信公众号“量子位”(ID:QbitAI),作者:问耕,36氪经授权发布。
来自德国弗莱堡大学的研究团队,最近有了一个好玩的发现。
AI又在打游戏时掌握了新技能。
“向死而生”
这个游戏是雅达利平台上的经典游戏Qbert:一个伪3D游戏,玩家需要控制角色(橙色章鱼)在立方体金字塔中跳跃,每成功一次,立方体就会变色。全部变色之后,就会进入下一关。而在这个过程中,需要躲避开障碍物和敌人。
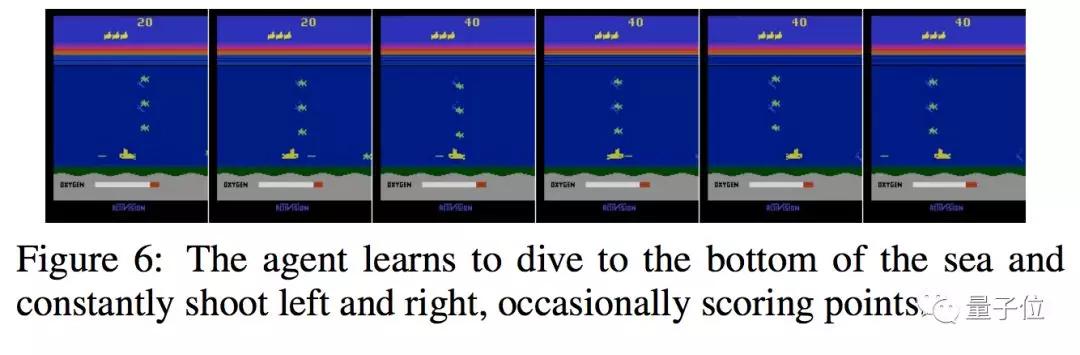
研究团队开发的AI智能体(agent)玩这个游戏时,开始还是普通玩法,按照规则累积积分。然后,智能体突然对过关失去兴趣。
相反,智能体开始“钓鱼”:站住不动,吸引敌人(紫色小球)来到身边,然后智能体操纵角色跳到敌人头上。这是一种杀敌的方法,也是自杀的方法。但是主动杀敌之后,能够产生足够多的分数来获得额外的生命奖励。


于是智能体开始一遍遍的重复这种向死而生的手法,如上图所示。
不止如此。
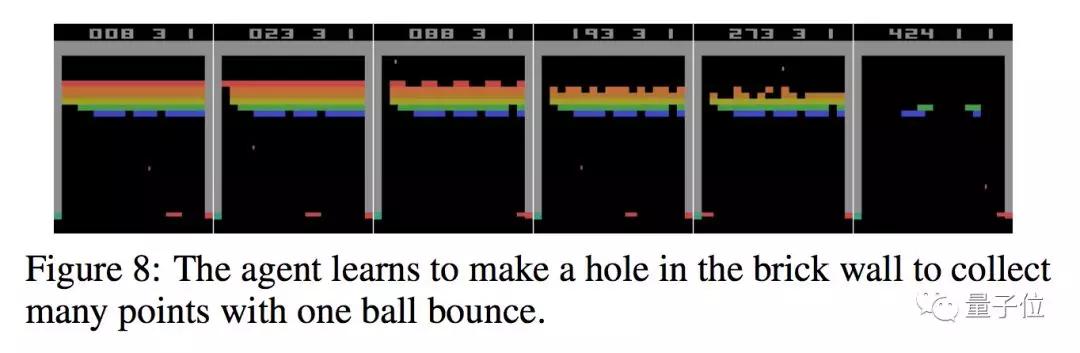
AI智能体还发现了一个Bug。在完成第一关之后,智能体操纵角色从一个立方体跳到另一个立方体,这似乎是一种随机的跳跃。但由于某种人类不了解的原因,游戏没有进入下一关,整个立方体金字塔开始闪烁。
然后智能体平白无故开始获得大量积分。如下图所示。

同样有意思的是,智能体也不是每次都能利用好这个bug。嗯,不是每次都能成。
当然还有其他的好玩的事儿,暂时按下不表。
不虚强化学习
当然,搞研究不是为了好玩。
弗莱堡大学的这个研究,主要关注的是进化策略(ES)。而且是一种非常基本的进化策略算法,没用镜像采样,没有衰减参数,没有任何高级优化。
在研究实验中,基于OpenAI Gym评估了八个雅达利游戏中的性能表现,这些游戏难度等级不同,简单的如Pong(乒乓)和Breakout(打砖块),复杂的如Qbert、Alien。此前,强化学习也都是在这些游戏上取得惊人的进展。
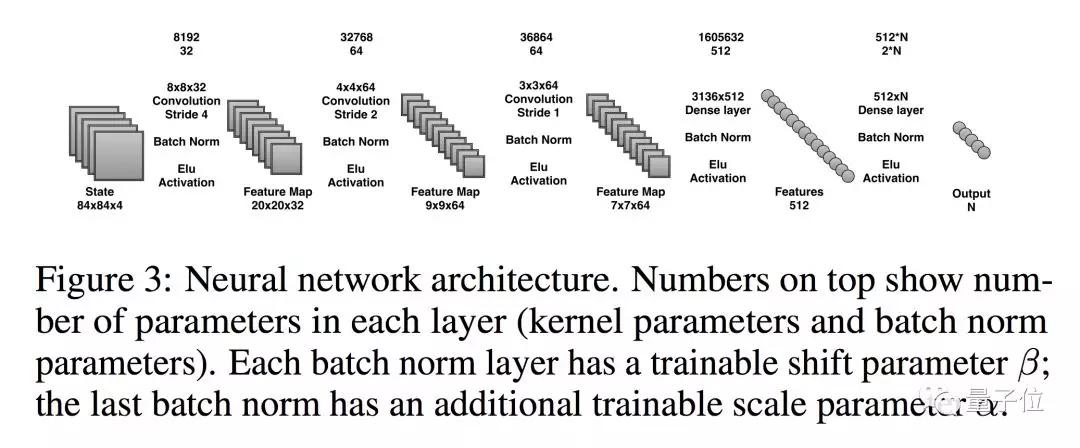
这个基于ES算法的AI,网络结构与原始DQN相同。变化之处,是把激活函数从ReLU变成了ELU,并增加了批量标准化层。
详细的研究过程,可以参考如下论文:Back to Basics: Benchmarking Canonical Evolution Strategies for Playing Atari
https://arxiv.org/abs/1802.08842
总之,研究团队得出结论:即便是非常基础的规范ES算法,也能实现和强化学习相同甚至更好的性能。
而且他们还定性地证明了,ES算法与传统的强化学习算法相比,也有非常不同的性能特征。在某些游戏中,ES算法能更好的学会探索环境,并能更好的执行任务。
当然在另外的一些游戏中,ES算法有可能陷入次优局部最小值。
研究团队表示,如果能把ES算法与传统强化学习算法结合,可能会出现强强联手的局面,并推动现有人工智能相关技术的新进展。
曾被LeCun硬怼
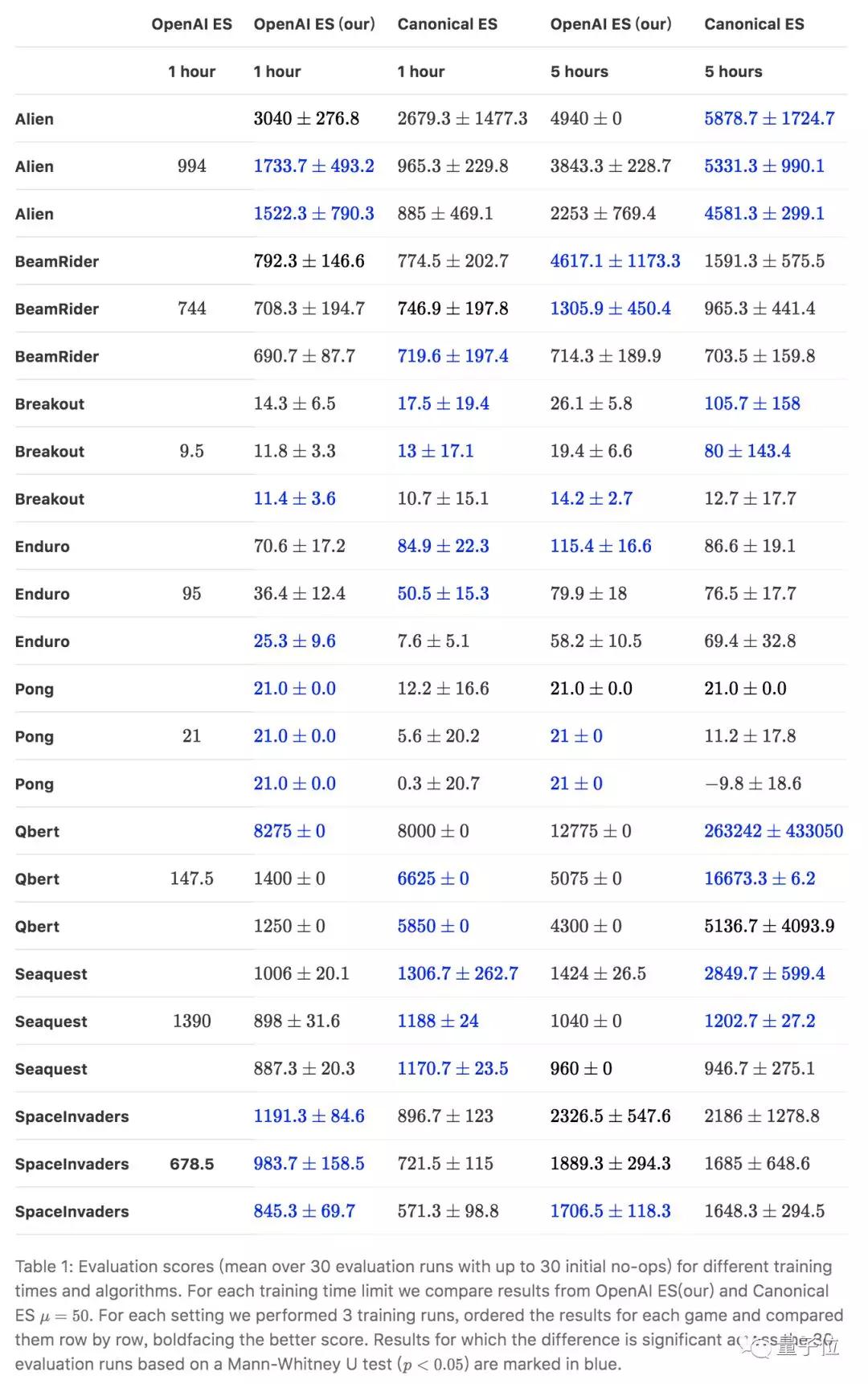
这次弗莱堡大学的研究,基于OpenAI此前发布的ES算法。当然,弗莱堡大学公布的成绩表明,他们的AI玩游戏更胜一筹。并且用了一张表进行了详细的对比。
他们把相关代码也公布在了GitHub上,地址如下:https://github.com/PatrykChrabaszcz/Canonical_ES_Atari
进化策略(ES)是一种已经发展了数十年的优化技术,去年OpenAI发表论文Evolution Strategies as a Scalable Alternative to Reinforcement Learning中指出,ES算法可以与强化学习方法媲美,耗时更少而且代码简单。
对这个理论感兴趣的同学,阅读论文请前往:https://arxiv.org/abs/1703.03864,以及GitHub地址在此:https://github.com/openai/evolution-strategies-starter 。
不过,当时这个理论遭遇Yann LeCun的正面硬刚。
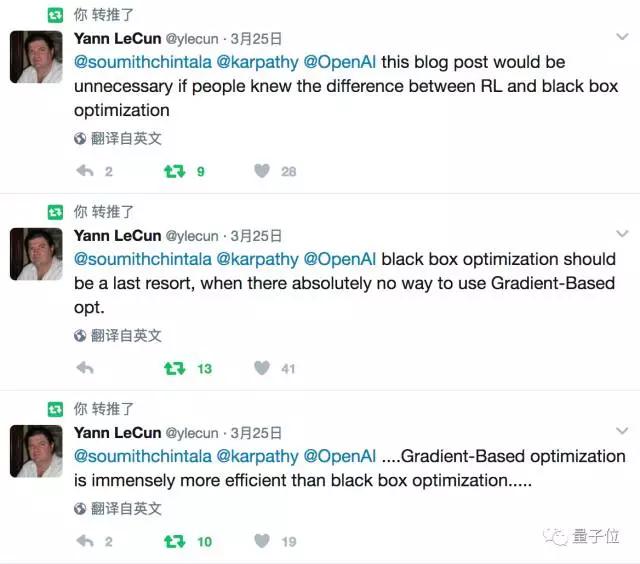
大意是说:
1、基于梯度的优化,远比黑箱优化更有效率
2、黑箱优化应该是最后的办法,无法基于梯度优化时才用
3、对于知道强化学习和黑箱优化的人来说,OpenAI这篇东西没什么用
不知道你们怎么看。
今天,就酱吧~


AI人工智能相关的软件
来画视频
- 3.7
(41)咨询产品免费试用美摄科技
- 3.8
(6)咨询产品免费试用火山引擎·机器学习平台
- 5.0
(1)咨询产品免费试用



大厂都在用的AI人工智能软件
Phrase TMS
- 4.0
(40)咨询产品免费试用UbiTrack多维高精度定位系统
- 5.0
(2)咨询产品免费试用Transifex
- 4.5
(40)咨询产品免费试用



限时免费的AI人工智能软件
火龙果写作
- 5.0
(1)咨询产品免费试用Copy.ai
- 4.4
(40)咨询产品免费试用阿里云×达摩院 视觉智能开放平台
- 5.0
(1)咨询产品免费试用



新锐产品推荐
法大大
- 3.9
(319)咨询产品免费试用闪闪
- 0.0
(0)咨询产品免费试用DevSuite
- 3.8
(17)咨询产品免费试用同创5U众创空间
- 0.0
(0)咨询产品免费试用融云
- 3.0
(1)咨询产品免费试用问卷星
- 3.8
(62)咨询产品免费试用







