什么样的工具,能让网站完成1800万次“抄袭”?
编者按:本文来自微信公众号“三节课”,作者 张成翼,36氪经授权转发。
近日,一篇文章突然在我的朋友圈中刷屏。

这篇题为《独家|估值175亿的旅游独角兽,是一座僵尸和水军构成的鬼城?》的文章,爆了一个大猛料。
估值约175亿人民币的独角兽公司马蜂窝21,000,000(别数了,两千一百万条)点评,其中有1800万条是从别的网站搬运而来的。抄袭来源包括且不限于携程、艺龙(都是友商)、穷游(这是直接竞品)、AGENDA(这也是竞品)、美团、大众点评(无辜躺枪)、Yelp(国外点评无辜躺枪)等多家点评与OTA网站。
不仅如此,文章中还提到,马蜂窝不仅抄袭,并且还造假。
许多官方抽奖活动,最终获奖者几乎都是马蜂窝内部员工或虚假账号,一个长期搬运内容的账号,竟然连续中奖12次。
本来说好的大奖,最后全变成了内部福利。这个操作实在是让人佩服~
而今早,马蜂窝官方也正式回应称,此事是有组织的进攻。

如果文章内容属实,那么这家成立八年之久,在无数驴友中颇具影响力的旅行攻略内容社区,也算是践行了自己的slogan——

自己办不到的,拿来就好。
不过,我在看完这篇文章的时候,比起文章的内容,更让我好奇的是:马蜂窝究竟是如何把这么多内容搬运到自己这里的?
毕竟,按照作者的说法,马蜂窝抄袭了1800万条点评,那么意味着,平均每天要搬运6600多条记录,这还不算问答和攻略,而且是在全年无休的情况下才能实现。全靠人力的话,马蜂窝整个公司啥都不用干了,天天Ctrl C+V就好了。
所以,这肯定是工具化解决。
三节课作为一家倡导“行胜于言”、“少空谈扯淡、多动手实操”的互联网人在线大学,一向喜欢基于具体的业务实践来对一些产品的新动向进行调研和分析,给从业者提供借鉴与参考。
今天,我们也立足于真实的业务场景,和大家谈一个互联网中非常重要,但又引发无数争议的工具——爬虫。
一、什么是爬虫?
你有没有用过抢票软件?
每当春运或者节假日期间,我们总能看到各种抢票软件在微信群中疯转。大家求爷爷告奶奶一般,希望你能帮忙点个加速,好能够早一点买到归家或旅行的车票。
但无论你如何努力,往往总是直到最后千钧一发之刻,才能拿到前往远方的车票。
这个让你可能又爱又恨的抢票软件,它的技术原理就是爬虫。
所谓爬虫,如果从技术原理上讲,它就是一个高效的下载工具,能够批量将网页下载到本地,留作备份。如果结合一些其他工具和算法,就能够实现,收集同一类型的网页,重复执行同一动作等行为。
简单讲,就是通过技术和算法模拟一个人在网络上的行为,像人一样点网页,像人一样下订单,只不过,相比起真人,他的效率高的异常。
它的工作状态有些像蚁群,每个蚂蚁的工作任务都非常简单,但是,当一大群蚂蚁重复相同的工作的时候,就能产生超乎寻常的效果。
比如说,如果你需要把全网关于某个关键词的网站全部收集汇总到一起(比如:三节课),这时,就是爬虫挨个查找所有关于三节课的信息,呈现到你的面前。
再比如说,当你想要找到12306中,某天所有北京到上海的余票,爬虫就可以帮助你不停地刷新网页,直到出现那张可以带你出发的车票。
在互联网世界,所有收集信息的过程,都离不开爬虫的参与。可以这样说,没有爬虫,就没有互联网。

▲图片来源网络
二、爬虫的善与恶
爬虫也分善恶。
爬虫最为广泛,也使人受益最大的应用就是搜索引擎。
现在,几乎所有有一定体量的app,都会有一个搜索框,通过搜索框,你可以查找到各种你需要的信息和内容,这是爬虫对人最大的价值。同时,也是支撑起谷歌近万亿美元市值的工具之一。
但是,并不会是所有的爬虫都像谷歌这样你好我好大家好,反而真的会像虫子一样惹人烦恼。
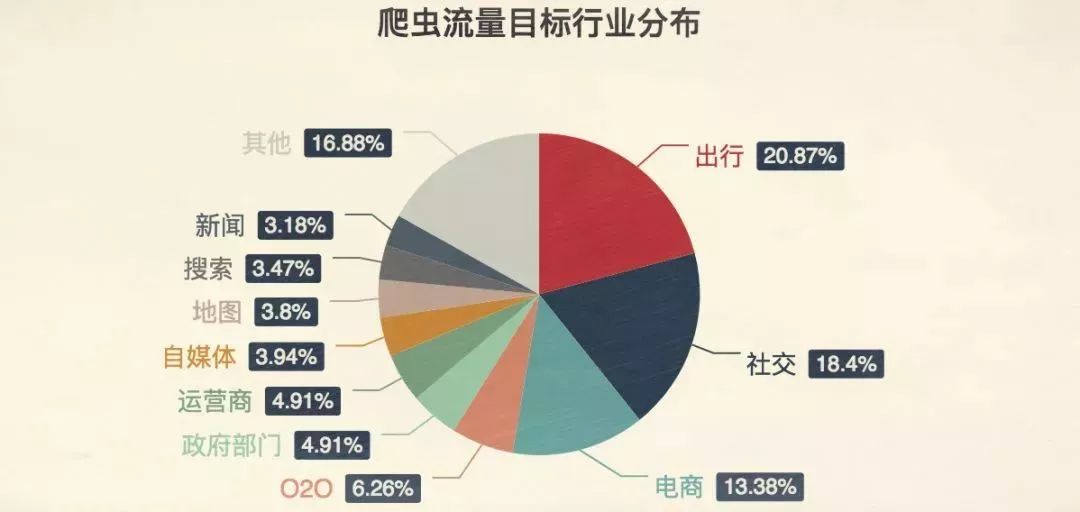
▲图片来源网络
上面这张图,显示了爬虫流量的主要去向,每个色块背后,都是一个真实而又强大的利益链条。这些流量的去向,就不再充满善意,更多情况下,是生长在灰色地带。
这些爬虫,或是为了一己私利,或是出于某些商业利益,对某一款app疯狂的骚扰,甚至影响了正常业务发展。这些爬虫,就是恶意的爬虫(虽然恶意,对于消费者来说可能并不是坏事,这里的恶意主要是指对被爬网站的恶意)。
接下来,我们来展示一下那些恶意爬虫应用,以及这些应用都是怎么赚钱的?
刷票软件
12306常年饱受爬虫软件的骚扰。
许多刷票软件,通过加价,或者要求分享转发的方式,帮助你买票,进而实现收入或者用户的增长。
这个看起来并不复杂的行为,其实带给12306巨大的压力。
你知道每年过年之前,12306 被点成什么样了吗?公开数据是这么说的——
“最高峰时1天内页面浏览量达813.4亿次,1小时最高点击量59.3亿次,平均每秒164.8万次。”
在每秒164.8万次点击背后,不仅是全国人民急切的回家之心,还有无数刷票软件带来的天量点击。
你可能还记得,前两年12306上线了奇葩的验证码,需要我们在一堆图片中,找到符合要求的一种。图片清晰度感人,要求奇葩,时不时会闹出各种各样的笑话。还有许多人在网上吐槽12306是不是故意刁难我们?

▲为推广传统文化,12306不遗余力
说实话,这真不是12306故意刁难我们,实在是饱受爬虫骚扰之后的无奈之举。许多人利用爬虫技术反复登录刷新,力求在新的余票出现之时,第一时间抢到票。
为了尽可能避免这种情况,尽可能让真人买到票,12306才不得不上线这些奇葩的验证码。许多爬虫只有最简单的点击和收集数据的能力,并不能识别图片,绝大多数爬虫都会被拦截。
但是,还是会有少部分的高阶玩家,攻破这道防线。
有一种东西叫做“打码平台”,你可以了解一下。
打码平台雇佣了很多叔叔阿姨,他们在电脑屏幕前不做别的事情,专门帮人识别验证码。
那边抢票软件遇到了验证码,系统就会自动把这些验证码传到叔叔阿姨面前,他们手工选好之后,然后再把结果传回去。总共的过程用不了几秒时间。
而且,这样的打码平台还有记忆功能。如果叔叔阿姨已经标记了某张图,那么下次这张图片再出现的时候,系统就直接判断。
时间一长,12306 系统里的图片就被标记完了,机器自己都能认识,叔叔阿姨都可以坐在一边斗地主了。
即使如此,还是做到了每秒164.8万次点击,如果没有这层防火墙,数量更是难以想象。
你可能会问,就算用了刷票软件又如何,抢到票不就好了?
且不说刷票软件带来的巨大的流量压力,需要为此多付出的服务器成本。为了防范刷票,不得不将注册和验证流程越搞越烦琐,平添无数烦恼。
而且,你用抢票软件买到了票,那么,不会使用抢票软件的叔叔阿姨们又该怎么办呐?
所以,这事不是你方便了就好。
僵尸粉大军
在微博上有一类粉丝,叫做“僵尸粉”。
我们经常能够看到一些微博名称中带着一长串数字,没有头像,却疯狂的转发一些热门评论,或者疯狂对着一个微博点赞转发,点开主页却一条微博都没有。这些没有头像,以数字命名的微博粉丝,就是僵尸粉。
它们按时上班,找到某个人的微博,疯狂的点赞留言转发关注,造成一种火热的幻觉。
僵尸粉的兴起,与爬虫也离不开关系。
就像我们说的,爬虫是模仿真人的行为,但是,只能模仿最简单的行为,比如说,按照事先安排好的文案和进行评论,再比如说,点赞转发加关注。所以,如果只看数据,不仔细分辨,往往能够瞒天过海。
许多僵尸粉每天日夜辛劳,刷赞刷评论刷关注,为微博的活跃数据添砖加瓦,贡献一份力量。
可是,微博不像是12306,可以靠买票赚钱,刷量又有什么用呐?
用处大了。
你是一个萌新用户,用爬虫伪造出10万粉丝,按时按点互动点赞留言。
广告主看到数据很开心,在你这里投放广告,提升注册数。可是你这都是爬虫的假账号,没有真人该咋办呐?
没事,你找不来人没关系,有爬虫啊。你有十万个爬虫账号,可以匀出一万来,点击注册账户,刷刷刷把数据刷上去,躺着就把钱赚了。。
再不济,有一个看起来火热的号,还可以乘着机会早日卖掉,这也换来一波不菲的收入。
最后,你还能靠买清粉工具再赚一波。
别人只是一石二鸟,你可能是一鱼三吃,实在是佩服。
而且,微博官方对这事其实心知肚明,只不过睁一只眼,闭一只眼罢了,毕竟,有了僵尸粉,数据还好看很多,何乐而不为呐?
返利电商刷低价
不知道你还记不记得有一类网站叫“聚合电商”“返利平台”等等等等。
这些网站,也是爬虫工具的受益者,它的基本原理和搜索引擎类似。
搜索引擎是将网页爬取过来,聚合在一起展示出来。
返利网站是将商品爬取出来, 聚合在一起展示出来,顺道把不同网站的商品做一个比价。
当然,无论是淘宝还是京东,对于这件事都是拒绝的,毕竟,谁也没法保证自己的每件商品就是全网最低价。如果都被返利网站展示出来,岂不就亏了。
不过,对于店铺来说,可能就不一样了,毕竟,多一个渠道就多一份销售额,在哪卖不是卖啊。
这类网站,原理和搜索引擎接近,盈利模式也差不多。
一方面,他们经常会设置竞价排名,通过花更多钱,获得更好的广告位,提升销售额。
如果觉得竞价排名良心过意不去,你还可以设置独立广告位,点击一次转一次的钱。
不过,最大头的收入还是做中间商,店铺每成交一单,店家适当给平台一些返利。
对于消费者来说,这可能不算什么坏事,不过,对于电商平台来说,可能不算好事,毕竟这些店铺能来网上卖货都是靠他们的努力,平白无故就被你抓取了,最后钱还让你赚走了,心情肯定不好。
社区批量抓取数据和内容
再有一类,就是文章开头提到的马蜂窝一类的网站。
其实,许多社区产品中的内容,大多数都是爬虫爬取而来,除了像马蜂窝,许多问答、文库或招聘网站都会通过爬虫获取内容。
毕竟,好内容自带流量,当你有了足够多的优质内容,也就有了足够大的流量,变现就很轻松了。
对此,被爬网站有时候也是睁一只眼,闭一只眼,管不管,全在于自己有没有这项业务。
最典型的例子就是领英,领英在2017年曾经将一家名为HiQ的数据分析企业告上法庭,原因是认定这家企业抓取领英用户的就职状态信息,提供给另外两家利用机器学习分析员工跳槽倾向和职业技能的企业。
结果却是即使打着保护用户隐私的旗号,领英仍然败诉并且被联邦法庭要求开放数据接口。
原因是HiQ已经这样爬取领英的数据长达五年,领英一直知情并且曾经去参加过HiQ组织的论坛峰会。如今领英自己开展了和HiQ类似的业务,就要断了HiQ的生路。
这和大多数网站对待爬虫的态度都很接近,当你规模不大,或者我还不准备做你这块的生意时,可以纵容你爬取我的信息,一定程度上,这个爬取过程还能提高我的受益。
但是,一旦超出我的承受范围,就要采取必要手段反击。
以上,就是爬虫常见的一些骚操作,说实话,这也只是窥其一角,爬虫在整个互联网中的应用,远超你的想象。
政务网站、搜索引擎、地图、自媒体等等等等一系列火热的应用,背后都有爬虫的身影,这也是为什么我们说,没有爬虫,就没有互联网。
三、爬虫二三问
说了关于爬虫的应用,关于爬虫,你可能还有些问题需要讨论一下。
这事违法吗?
大多数并不会。
目前尚没有任何法律明确规定,类似爬虫这样的行为违法。
即使是马蜂窝,你可以说他侵权,但是,如果他将自己定位以为平台的话,那些将其它网站内容放在马蜂窝的行为,其实也是用户自发,与平台无关。
毕竟,就像我们说的,爬虫毕竟也只是模仿人的行为,难道,你要因为一个人或一群人点击次数过于密集而惩罚他吗?
所以,爬虫本身并不违法。但是,你如何使用爬虫获取的数据和信息,大多数情况都是有明确的规定的。
比如说,你将别人有明确版权的文章或者图片爬取出来,作为商用,这无疑是侵权行为,我当然可以告你。
再比如说,你爬取一些个人隐私数据,公开买卖,也是违法行为,我也是可以处理的。
所以——
我究竟应该如何看待爬虫?
对于个人而言,爬虫作为高效的信息和数据获取工具,一定是互联网人的必备技巧,他将大幅节省你的时间,极大程度提高你的工作效率。
举个最简单的例子,作为一个新媒体从业者,我会把一些我喜欢的公众号文章通过爬虫爬取下来,进行分析对比,这要比我一篇一篇的看效率高多了。
比如说竞品分析、行业研究、人群画像等工作,通过爬虫,你可以只需要几分钟的时间,就能够将某一类数据全部爬取下来,然后有针对性的进行数据分析,优化你的行文。
对于公司来说,爬虫的应用空间就更为巨大了。
这两年火热的今日头条就是典型案例,不太严谨的说,今日头条核心就是做了三件事——
把网络上所有的资讯文章,以及用户在社交网站上的数据爬取下来。
把这些数据进行分类打标签,进行一一对应。
将拥有同类标签的文章和用户进行匹配。
通过高效的应用搜索引擎和个性化推荐功能,将传统的人找信息的分发模式,转变为信息找人的分发模式,帮助其成为一家独角兽。
你或许做不成下一个今日头条,但是,拥有更多的数据能够帮助你做成的事情,超过你的想象。
但是,技术虽然有价值,如何使用技术就成为新的问题。
马蜂窝这次的事件发生,给我们提了个醒,很多创业公司早期,都难免会在灰色地带做一些事情。
毕竟当初整个互联网世界还是一片蛮荒,大家都在跑马圈地,你不干,就有别人干,生存第一,虽然原则上不能原谅,但是情感上也能理解。
但是,当你已经成为一家成熟的大公司时,就必须承担必要的责任和底线。
在很多时候,应用爬虫其实是一个零和游戏,一方受益就代表着另一方受损,会使用抢票软件的人就会使不使用抢票软件的人受损;使用僵尸粉刷量的人,抢夺的是那些辛辛苦苦做内容的媒体人的空间;返利平台则是直接截了电商的胡。
很难说在这场竞争中究竟孰是孰非,孰优孰劣。但是,一旦我们的竞争,并没有让大家变得更好,或者是以一方付出更高的代价来实现的,这件事真的还合理吗?
在三节课内部,我们一直有这样一种看法——
对于在互联网行业做产品还是做运营的所有人来说,我们工作的最大意义,正是在于“我们在运用着自己力所能及的一些方法和工具,一点点在让这个世界变得更加完整和美好”的可能性。
而爬虫也应该是在这个过程中可以运用到一种工具和方法,用这个能量巨大的工具,让我们自己,也让我们所处的环境变得更好,不也更有意义吗?
按照马蜂窝的回应,网站存有抄袭,但也只是小范围存在,并没有达到1800万条的规模。
无论如何,我们都希望这次马蜂窝能够从中吸取教训,真正能够培植起自己独有的内容生产体系和架构,成为一家更让人热爱的旅游攻略平台。
毕竟,不忘初心,也算是互联网人的必备技巧了。
本文中借鉴了不少浅黑科技史中老师的《我收到一份<中国焦虑图鉴>》,行文仓促,一时没有获得授权。如有冒犯,会及时修改处理。



数据分析相关的软件
永洪BI
- 4.3
(51)咨询产品免费试用观远数据
- 4.0
(30)咨询产品免费试用帆软FineBI
- 4.2
(112)咨询产品免费试用



行业专家共同推荐的软件
Wyn Enterprise
- 4.2
(49)咨询产品免费试用微软 Power BI
- 3.8
(53)咨询产品免费试用DigiPrime
- 4.7
(36)咨询产品免费试用



限时免费的数据分析软件
亿信ABI
- 3.9
(23)咨询产品免费试用派可数据
- 4.4
(31)咨询产品免费试用云眼
- 5.0
(1)咨询产品免费试用



新锐产品推荐
Teambition
- 3.7
(90)咨询产品免费试用谐云科技
- 0.0
(0)咨询产品免费试用水木知行
- 0.0
(0)咨询产品免费试用云创cStor C1000云存储系统
- 0.0
(0)咨询产品免费试用融云
- 3.0
(1)咨询产品免费试用天润融通
- 4.4
(33)咨询产品免费试用







