能追踪吴京的人脸识别技术,现实中能实现吗
编者按:本文来自微信公众号“乌镇智库”(ID:WUZHEN-INSTITUTE),作者聪聪;36氪经授权发布。
近日,军事动作影片《战狼2》的相关信息成功占据了人们的视线,出彩的不仅是其中的动作打斗,影片中出现的高科技武装设备也成功将人们的目光转移到科技领域上。
影片中最精彩、最经典的桥段之一就是雇佣兵利用基于人脸识别的无人机手控追踪,并精确瞄准、实时射击,雇佣兵们凭借这一技术为主角制造了不少的麻烦。

无人机的其他表现如持续射击、装载小型火箭弹,我们暂且不作分析,但人脸识别技术是否能够达到如影片中的技术水准,本文为你解答人脸识别技术的秘密。
真实世界的人脸识别
据雷锋网报道,目前基于相关技术的无人机虽然已经有了一些跟踪、打击犯罪、恐怖分子的能力,但还不足以识别人脸、精确打击。零度智控CEO杨建军解释说,在夜晚环境中,加配人脸识别的无人机想要拍摄到人体必须在50米以内,如要要看清人脸必须在15米以内,这种应用不太适合旋翼机,更适合中高空固定翼侦察机。但他同时判断,这肯定是未来无人机发展的趋势之一。
如果利用无人机单纯识别人脸的话,有个直观的对比。自动驾驶车辆车载前置相机识别红绿灯,如果汽车前置相机离红灯10米开外的话,红绿灯在相机中所占的像素就非常少,尤其下采样后,也就是几十个pixel(甚至更少),如果超过20米、30米或者更远,在像素点更少的情况下,很难通过像素点去识别灯光;
同理,在实际生活中,无人机在几十米开外很难识别人类面部具体的细节特征;另外无人机的拍摄高度远高于一般监控镜头的设置高度,要拍摄清晰的人脸影像殊不容易;再者无人机机载嵌入式芯片因为考虑的因素众多,会首选低功耗,因此用的多的也是Xilinx ZQNQ的芯片、ZYNQ的性能,所以即使跑AlexNet的256*256这种量级都跑不到实时。
大华股份解决方案工程师张生强则表示,在对于距离远造成的像素点降低的问题,大华有了合理的处理方案。但大华无人机在加配人脸识别时也遇到了一些问题,主要是人脸获取的有效性。他解释说,一般人脸识别相机都是安装在车站、机场等通道或者是入口处,拍摄的角度都是固定的,对于人脸的采集成功率比较高,但是无人机拍摄的画面和角度都是不固定的,最开始的视角不一定能刚好拍到正面人像,需要不断机动飞行。
人脸识别技术的学习方法
人脸识别是计算机视觉研究领域的一个热点,研究领域非常广泛。对于人脸样本的获取来进行算法学习至关重要,以下以在LFW数据集上(Labeled Faces in the Wild)获得优秀结果的方法和采用深度学习的方法来进行分析。
LFW数据集(Labeled Faces in the Wild)是目前用得最多的人脸图像数据库。该数据库共13233幅图像,共5749个人,其中1680人有两幅及以上的图像,4069人只有一幅图像。图像为250*250大小的JPEG格式。绝大多数为彩色图,少数为灰度图。该数据库采集的是自然条件下人脸图片,目的是提高自然条件下人脸识别的精度。
识别算法要完成的工作是人脸验证(Face verification),即判断给定的两张图片(一对)中的人脸是否来自同一个人。
LFW将数据集分作两大块,用做供研究人员选择其算法模型所用,包括一个训练集和一个测试集,不管是训练集还是测试集,其图片都是由M对来自同一人脸的图像和N对来自不同人脸的图像构成;当确定了模型后,算法将在[View 2]上实验,[View 2]包含10个子集,每个子集构成规则同刚讲到的训练集或测试集,实验过程大抵为:
A、每次从10个子集中选一个做为测试集,其余9个做为训练集;
B、通过训练集确定模型的参数;
C、对测试集进行预测;
D、计算预测的准确度;
进行十次之后,平均的准确度即为该算法在LFW上的识别准确度,GaussianFace的98.52%即是如此计算的。
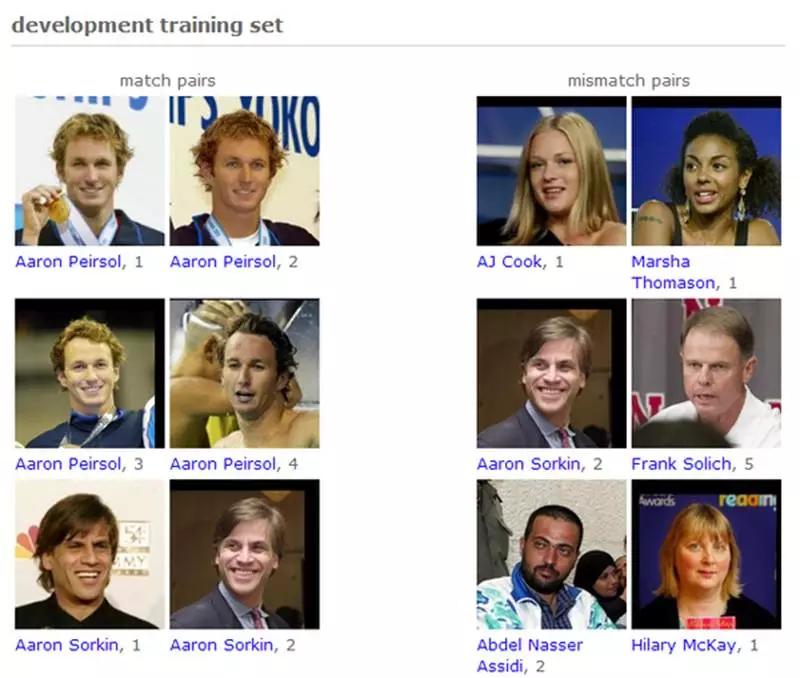
训练集示例

人类在LFW数据集上的识别精度
八种人脸识别学习方法
1,face++(0.9950)
参考文献:Naive-Deep face Recognition: Touching the Limit of LFWBenchmark or Not?
face++从网络上搜集了5million张人脸图片用于训练深度卷积神经网络模型,在LFW数据集上准确率非常高。该篇文章的网路模型很常规(常规深度卷积神经网络模型),但是提出的问题是值得参考的。
问题一:他们的Megvii Face Recognition System经过训练后,在LFW数据集上达到了0.995的准确率。在真实场景测试中(Chinese ID (CHID)),该系统的假阳性率非常低。但是,真阳性率仅为0.66,没有达到真实场景应用要求。其中,年龄差异(包括intra-variation:同一个人,不同年龄照片;以及inter-variation:不同人,不同年龄照片)是影响模型准确率原因之一。而在该测试标准(CHID)下,人类表现的准确率大于0.90.
在CHID中出错的样本
问题二:数据采集偏差。基于网络采集的人脸数据集存在偏差。这些偏差表现在:1,个体之间照片数量差异很大;2,大部分采集的照片都是:微笑,化妆,年轻,漂亮的图片。因此,尽管系统在LFW数据集上有高准确率,在现实场景中准确率很低。
问题三:模型测试加阳性率非常低,但是现实应用中,人们更关注真阳性率。
问题四:人脸图片的角度,光线,闭合(开口、闭口)和年龄等差异相互的作用,导致人脸识别系统现实应用准确率很低。
2,DeepFace(0.9735 )
参考文献:Deepface: Closing the gap to humal-level performance in faceverification
常规人脸识别流程是:人脸检测-对齐-表达-分类。本文中,我们通过额外的3d模型改进了人脸对齐的方法。然后,通过基于4million人脸图像(4000个个体)训练的一个9层的人工神经网络来进行人脸特征表达。模型在LFW数据集上取得了0.9735的准确率。
3,FR+FCN(0.9645 )
参考文献:Recover Canonical-View Faces in the Wild with Deep NeuralNetworks
自然条件下,因为角度,光线,occlusions(咬合/张口闭口),低分辨率等原因,使人脸图像在个体之间有很大的差异,影响到人脸识别的广泛应用。本文提出了一种新的深度学习模型,可以学习人脸图像看不见的一面。因此,模型可以在保持个体之间的差异的同时,极大的减少单个个体人脸图像(同一人,不同图片)之间的差异。与当前使用2d环境或者3d信息来进行人脸重建的方法不同,该方法直接从人脸图像之中学习到图像中的规则观察体(canonical view,标准正面人脸图像)。作者开发了一种从个体照片中自动选择/合成canonical-view的方法。在应用方面,该人脸恢复方法已经应用于人脸核实。
4,DeepID(0.9745 )
参考文献:DeepID3: Face Recognition with Very Deep Neural Network
深度学习在人脸识别领域的应用提高了人脸识别准确率。本文使用了两种深度神经网络框架(VGG net 和GoogleLeNet)来进行人脸识别。两种框架ensemble结果在LFW数据集上可以达到0.9745的准确率。文章获得高准确率主要归功于大量的训练数据,文章的亮点仅在于测试了两种深度卷积神经网络框架。
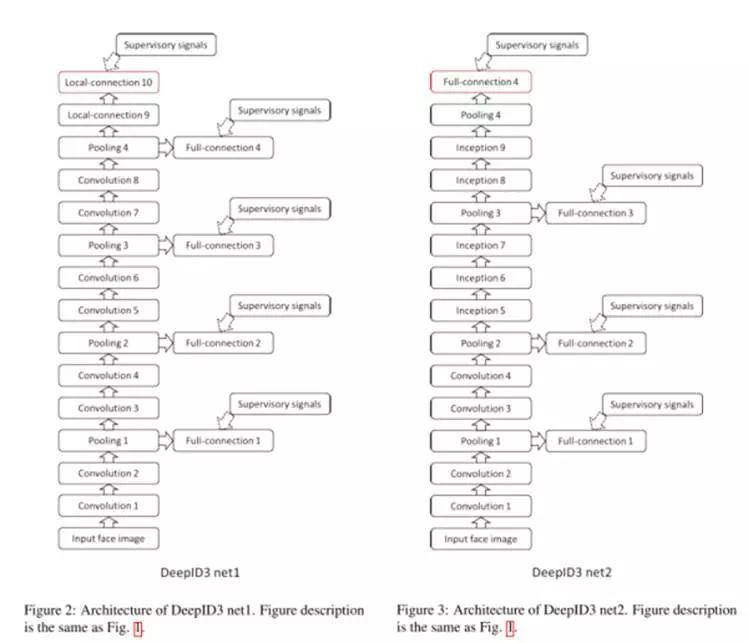
两种深度卷积神经网络框架
5,FaceNet(0.9963)
参考文献:FaceNet: A Unified Embedding for Face Recognition andClustering
作者开发了一个新的人脸识别系统:FaceNet,可以直接将人脸图像映射到欧几里得空间,空间的距离代表了人脸图像的相似性。只要该映射空间生成,人脸识别,验证和聚类等任务就可以轻松完成。该方法是基于深度卷积神经网络,在LFW数据集上,准确率为0.9963,在YouTube Faces DB数据集上,准确率为0.9512。FaceNet的核心是百万级的训练数据以及 triplet loss。
6,baidu的方法
参考文献:Targeting Ultimate Accuracy : Face Recognition via DeepEmbedding
本文中,作者提出了一种两步学习方法,结合mutil-patch deep CNN和deep metric learning,实现脸部特征提取和识别。通过1.2million(18000个个体)的训练集训练,该方法在LFW数据集上取得了0.9977的成绩。
人脸不同区域通过深度卷积神经网络分别进行特征提取
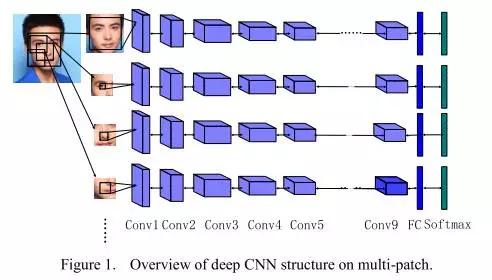
multi-patch示意图
深度卷积神经网络提取的特征再经过metric learning将维度降低到128维度
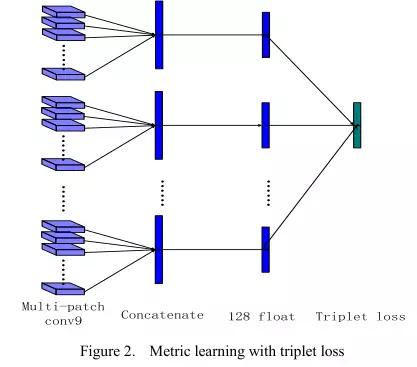
metric learning示意图
7,pose+shape+expression augmentation(0.9807)
参考文章:Do We Really Need to Collect Millions of Faces for EffectiveFace Recognition
该文章的主要思路是对数据集进行扩增(data augmentation)。CNN深度学习模型,比如face++,DeepID,FaceNet等需要基于百万级人脸图像的训练才能达到高精度。而搜集百万级人脸数据所耗费的人力,物力,财力是很大的,所以商业公司使用的图像数据库是不公开的。
本文中,采用了新的人脸数据扩增方法。对现有公共数据库人脸图像,从pose,shape和expression三个方面合成新的人脸图像,极大的扩增数据量。在LFW和IJB-A数据集上取得了和百万级人脸数据训练一样好的结果。该文章的思路很好,适合普通研究者。
pose(角度)生成示意图
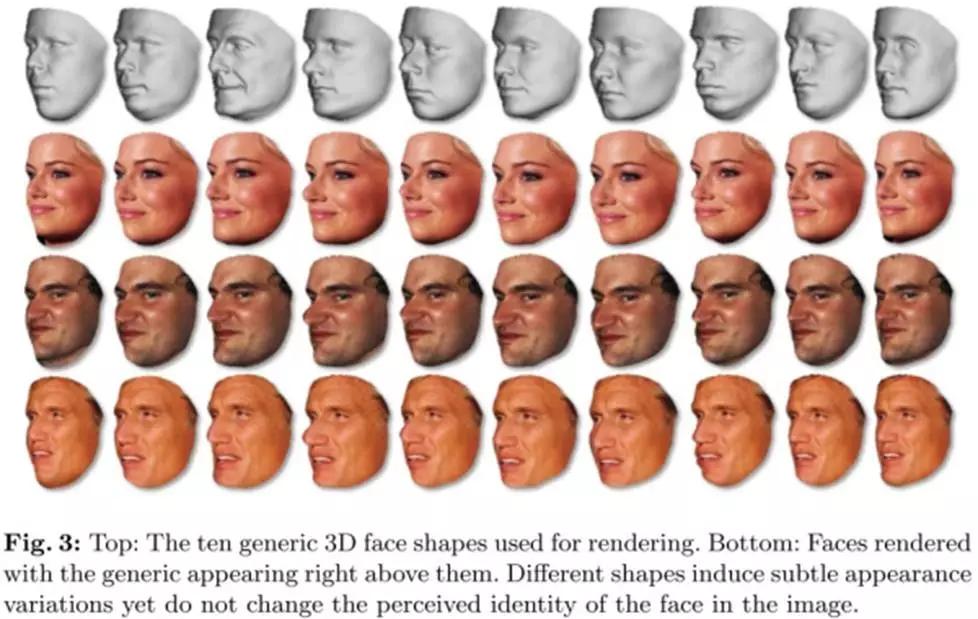
不同脸型生成示意图
8, CNN-3DMM estimation(0.9235)
参考文献:Regressing Robust and Discriminative 3D Morphable Models with avery Deep Neural Network(推荐阅读原文)
当在真实场景中应用3d模拟来增加人脸识别精度,存在两类问题:要么3d模拟不稳定,导致同一个个体的3d模拟差异较大;要么过于泛化,导致大部分合成的图片都类似。因此,作者研究了一种鲁棒的三维可变人脸模型(3D morphable face models (3DMM))生成方法,采用了卷积神经网络(CNN)来根据输入照片来调节三维人脸模型的脸型和纹理参数。该方法可以用来生成大量的标记样本。该方法在MICC数据集上进行了测试,精确度为state of the art 。与3d-3d人脸比对流程相结合,作者在LFW,YTF和IJB-A数据集上与当前最好成绩持平。文章的关键点有两个:一,3D重建模型训练数据获取;二,3D重建模型训练。
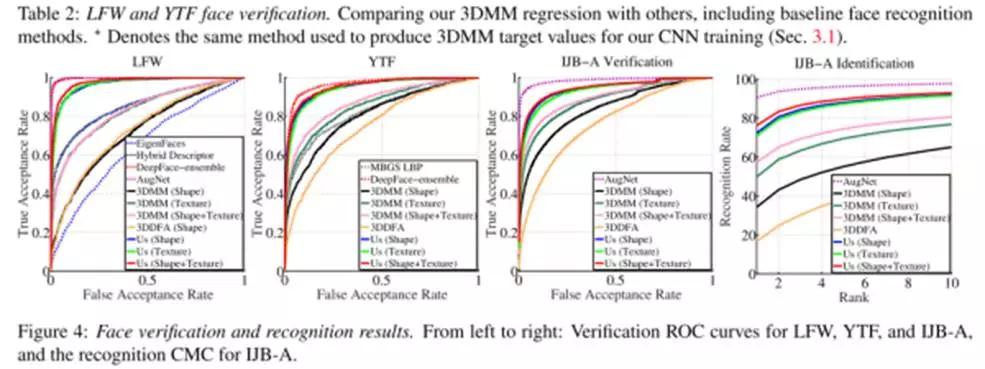
YTF和IJB-A测试结果
上述方法可以分为两大类:
第一类:face++,DeepFace,DeepID,FaceNet和baidu。他们方法的核心是搜集大数据,通过更多更全的数据集让模型学会去识别人脸的多样性。这类方法适合百度/腾讯/谷歌等大企业,未来可以搜集更多更全的训练数据集。数据集包扩同一个体不同年龄段的照片,不同人种的照片,不同类型(美丑等)。通过更全面的数据,提高模型对现场应用中人脸差异的适应能力。
第二类:FR+FCN,pose+shape+expression augmentation和CNN-3DMM estimation。这类方法采用的是合成的思路,通过3D模型等合成不同类型的人脸,增加数据集。这类方法操作成本更低,更适合推广。其中,特别是CNN-3DMM estimation,作者做了非常出色的工作,同时提供了源码,可以进一步参考和深度研究。
上述方法在理想条件下的人脸识别精确度已经达到或者超越人类的表现。但是,由于光线,角度,表情,年龄等多种因素,导致人脸识别技术无法在现实生活中广泛应用。未来研究中,不管哪种思路,均是提高模型对现场复杂环境的适应能力,在复杂环境中,也能达到人类识别的精确度。
总之,目前的人脸识别应用并不能普及化地被识别对象放置于生活场景的应用,而且不容许被动失败。这样应用中,大家当然觉得人脸识别还挺成熟。但当我们考虑到全网人脸搜索,SNS上人脸识别的时候,问题的难度便呈几何级增长。
部分内容引用自雷锋网,作者:张栋
作者:狗头山人七
网址:https://zhuanlan.zhihu.com/p/24816781
作者:邹哥亮
网址:https://www.zhihu.com/question/23829815



AI人工智能相关的软件
来画视频
- 3.7
(41)咨询产品免费试用美摄科技
- 3.8
(6)咨询产品免费试用火山引擎·机器学习平台
- 5.0
(1)咨询产品免费试用



大厂都在用的AI人工智能软件
Phrase TMS
- 4.0
(40)咨询产品免费试用UbiTrack多维高精度定位系统
- 5.0
(2)咨询产品免费试用Transifex
- 4.5
(40)咨询产品免费试用



限时免费的AI人工智能软件
火龙果写作
- 5.0
(1)咨询产品免费试用Copy.ai
- 4.4
(40)咨询产品免费试用阿里云×达摩院 视觉智能开放平台
- 5.0
(1)咨询产品免费试用



新锐产品推荐
云千载
- 4.0
(1)咨询产品免费试用DevSuite
- 3.8
(17)咨询产品免费试用水木知行
- 0.0
(0)咨询产品免费试用理臣咨询
- 0.0
(0)咨询产品免费试用德国莱茵TUV
- 0.0
(0)咨询产品免费试用






