医生水平大PK: 人工智能四胜三平一负绝对领先
编者按:本文由微信公众号“新智元”(ID:AI_era)来源:spectrum.ieee. 作者:熊笑,36氪经授权发布。
IEEE Spectrum 日前公布了一个“记分牌”,显示了在医疗领域的各个子类中,AI 和人类医生谁更占优势。用 IEEE Spectrum 的话说,“AI 正在医疗领域对医生发起挑战,我们一直在记分”。
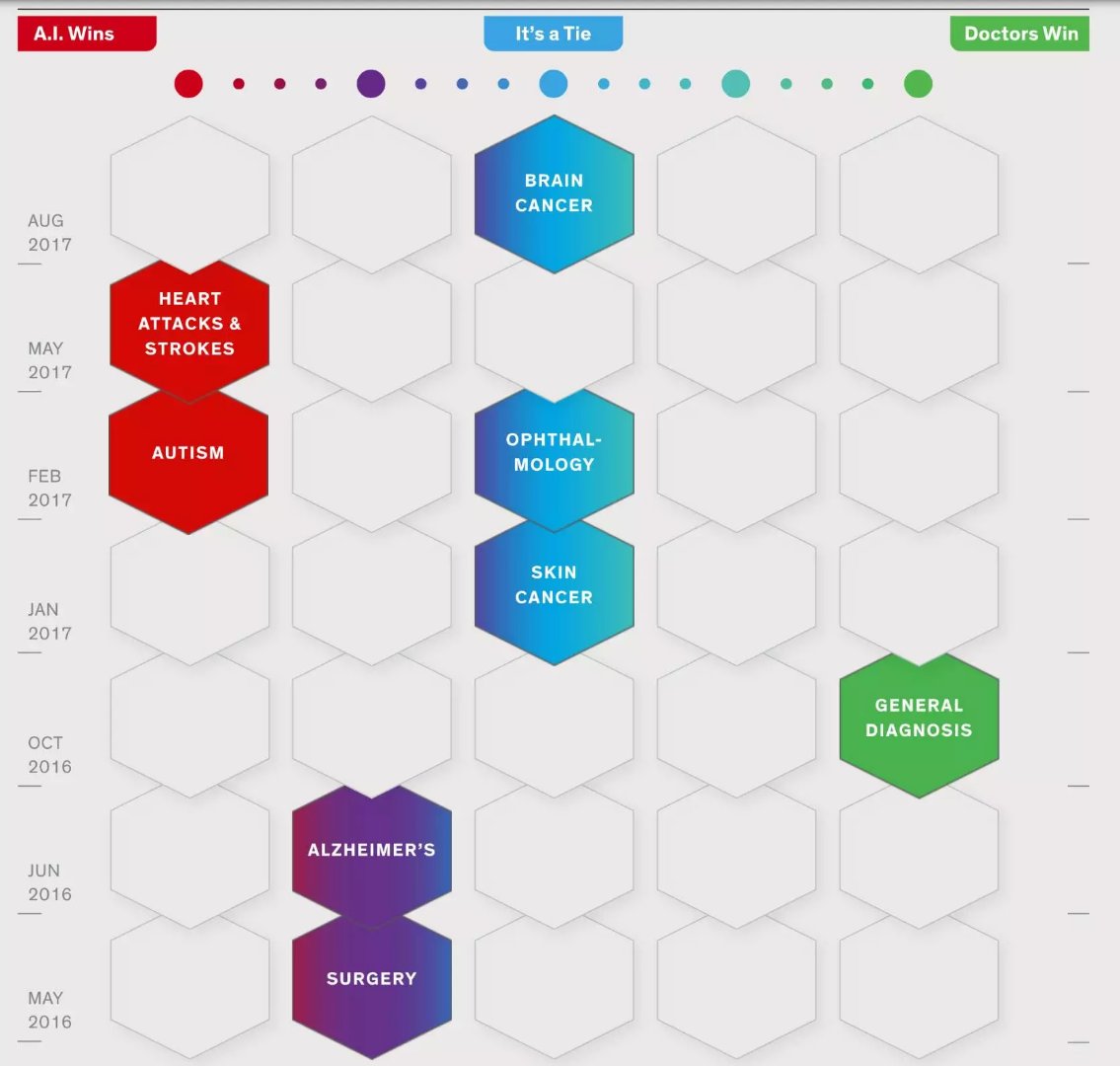
这个记分牌显示——
AI 占据明显优势的是心脏病、中风和自闭症;
AI 占据一定优势的是阿兹海默、外科手术;
AI 和人类医生打个平手的是脑肿瘤、眼科、皮肤癌;
人类医生占据明显优势的是一般性诊断。
心脏病:与标准预测方法相比,AI系统多预测正确了355 个患者的病情
英国诺丁汉大学的研究人员创建了一个系统,该系统通过扫描患者的常规医疗数据,可以预测10年内哪些患者有心脏病发作或中风的危险。与标准预测方法相比,AI系统多预测正确了355 个患者的情况。
研究者Stephen Weng和他的同事在英国378,256 名患者的医疗记录上测试了几种不同的机器学习工具。这些记录记载了2005 年到2015 年患者的健康状况,并包括了一些人口学、医疗条件、处方药、就诊记录、实验室结果等信息。
研究人员将病历记录中的 75% 投喂到他们的机器学习模型中,该模型旨在找出10 年内经历了心脏病发作或中风的患者的特征。然后,研究小组在另外25%的记录中测试了模型,看看它们预测心脏病发作和中风的准确程度如何。他们还用该记录的子集测试了标准预测方法的准确度。
使用1.0分表示100%准确度,标准方法得分为0.728。机器学习模型的准确率则从0.745到0.764,神经网络机器学习模型的得分最高。
也就是说,神经网络模型在7,404 例实际发生心脏病或中风的病例中正确预测出了4,998名患者,比标准方法高出355 名。有了这样的预测,医生就可以采取预防措施,如开处方药降低胆固醇。
自闭症:仅使用三个变量,算法检测出了10 名自闭症儿童中的8名
北卡罗来纳大学的一个研究团队检测到了6个月大的儿童与自闭症相关的大脑发育变化。深度学习算法能够使用这些数据来预测在24个月内,有罹患自闭症高度风险的儿童是否能被诊断出该病。
该算法正确预测高危儿童的最终诊断准确率为81 %,灵敏度为88%。与行为调查问卷相比,这无疑是更有帮助的结果——这些调查问卷诊断早期自闭症(大约12个月大),只有50%的准确性。
UNC 心理学家和大脑发育研究员资深作者Heather Hazlett说:“这优于以前那些办法,并且能在儿童更小时就做出诊断。”
这一算法运行良好,仅使用三个变量——脑表面积,脑容量和性别(男孩比女孩更容易发生自闭症)——该方法检测出了10 名自闭症儿童中的8名。
据研究团队成员、UNC神经图像分析和研究实验室联合主任MartinStyner 说,训练该算法的团队最初使用了一半的数据训练,另一半用于测试。但是,根据评议人员的要求,他们随后进行了更为标准的 10-fold 分析,其中数据被细分为10 个相等的部分。然后机器学习的过程进行10 轮,每轮用9 部分训练,保留一部分用于测试。最后,最后收集10轮的“仅测试”结果,用于其预测。
幸运的是,Styner 说,两种类型的分析 - 初始的50/50和最后的10-fold- 显示了几乎相同的结果。该团队对预测精度感到满意。
当然,Hazlett 也表示,项目的推进和普及还需要一些时间,“这样昂贵的诊断测试不是所有的家庭都能负担得起。”
阿尔茨海默:新方法可能没有比旧的好太多,也许只是因为它使用了更好的数据
哈佛大学、马萨诸塞州总医院和华中科技大学的研究者合作设计了一项将fMRI脑扫描与临床资料结合起来进行预测的方案。
马萨诸塞州总医院临床数据科学中心的高级研究员QuanzhengLi说:“我们试图在早期发现阿尔茨海默。很多人尝试使用传统的机器学习方法来做到这一点,但结果并不那么好,因为这是一个非常困难的问题。”
初步测试后,研究人员表示,他们的深度学习程序与特殊的fMRI数据集配对时,比使用更基本的数据集的其他分类方法更准确。然而,当这些传统分类器也使用特殊数据集时,它们在精度上也有类似的增益。
爱丁堡大学生物医学工程师Javier Escudero表示,这个新方法可能没有比旧的好太多,可能只是因为它使用了更好的数据。
如果是这样,那么想要借助深度学习方法诊断阿尔茨海默病的其他专家可能想要仔细观察他们纳入分析的数据。根据这项最新的研究,显示大脑区域之间关系的fMRI扫描提供了比仅随时间变化记录测量结果更细微的视图。
研究团队想看看他们是否可以使用功能连接中的这些变化来预测阿尔茨海默病。他们从阿尔茨海默病神经影像学计划提供的93 名MCI患者和101 名正常患者的数据开始。根据从参与者大脑中90个区域获取的130 次fMRI测量的时间序列,研究人员可以知道一段时间内信号闪烁的位置。
接下来,在关键步骤中,研究者处理了该数据集,以便对相关脑区域中信号强度进行二次测量。换句话说,他们构建了一个功能连通图,显示哪些区域和信号彼此最密切相关。
最后,该团队构建了一个深度学习程序,可以解释这些模式,并结合年龄、性别和遗传风险因素等临床资料,预测一个人是否会发展成为阿尔茨海默病。
最后,该团队说,其使用特殊处理的功能连接数据集的程序,在其数据集中预测患者是否会得阿尔茨海默病的准确率,接近90%。
手术:在60%的试验中,STAR完全自主地完成了手术的规划和执行

智能手术机器人在计划并执行手术,虽然监督者会偶尔进行帮助
机器人已经可以使用自己的视觉、工具和智能来缝合猪的小肠。更重要的是,SmartTissue Autonomous Robot(STAR)在操作上表现得比人类外科医生更好。
STAR 的发明者并没有声称机器人可以很快在手术中取代人类。相反,他们使用了“有监督的自动化”的概念。
研究者之一、儿童外科医生 Peter Kim 表示医生的工作并没有受到威胁。他说:“如果有一台能够与我们一起工作以改善手术结果和安全性的机器,将是一件大好事。”
研究人员对他们的机器人进行了编程,进行了称为肠缝合的手术——将被切割的肠段缝合在一起。该团队的高级工程师RyanDecker说,缝合线必须紧密而有规律地隔开,以防止泄漏。经验丰富的人类外科医生同样执行了相同的任务。当比较所得到的缝合线时,STAR 的针脚更加一致,更能防止泄漏。

在大约40%的实验中,研究人员进行了干预,提供了某种类型的指导。在其他60%的试验中,STAR完全自主地完成了这项工作。
人类外科医生可以对手术进行,让机器做更多的例行或繁琐操作。
STAR通过整合几种不同的技术来解决软组织带来的挑战。其视觉系统依赖于放置在肠组织中的近红外荧光(NIRF)标签;一个专门的NIRF 摄像机跟踪这些标记,而3D摄像机记录整个外科手术的图像。结合所有这些数据,STAR能够将其重点放在目标上。机器人自己制定了缝合任务的计划,并且随着组织在运行过程中的移动,它自动调整了该计划。
脑肿瘤:IBM Watson只花了10分钟就分析了患者的基因组并提出了治疗计划,专家则花了160个小时
在治疗脑肿瘤时,时间至关重要。在一项新的研究中,IBM Watson只花了10分钟就分析完成了脑肿瘤患者的基因组并提出了治疗计划。但是,尽管人类专家花了160个小时来制定计划,但研究结果并不表明机器对人类取得了全胜。
该病人是一名76岁的男子,他对医生抱怨头痛,步行困难。大脑扫描显示出肿瘤,外科医生迅速进行治疗。该男子接受了三周的放射治疗,并开始了长期的化疗。尽管得到了最好的照顾,他一年内就去世了。虽然Watson 和医生分析了患者的基因组,提出治疗计划,但是当他的组织样本被测序时,患者已经每况愈下。
领导 Watson 基因组团队的LaxmiParida 解释说,大多数癌症患者没有扫描其全部基因组(由30亿单位的DNA组成)。相反,他们通常做的是一个“小组”测试,只检测一些已知在癌症中发挥作用的基因亚组。
研究人员想知道如果扫描患者的整个基因组,虽然比运行“小组”测试更昂贵和耗时,但是否能为医生设计治疗计划提供出真正有用的信息。
这个问题的答案是肯定的。 NYGC 临床医生和 Watson 都确定了在panel 测试中未检查出的基因突变,提出了可能有作用的药物和临床试验。
其次,研究人员想比较由IBM Watson和NYGC的医学专家进行的基因组分析。
Watson 和专家组都收到了患者的基因组信息,他们确定出显示突变的基因,通过医学文献了解这些到突变是否在其他癌症病例中被发现,寻找药物成功治疗的报告,并检查对患者可行的临床试验。人类花费了“160个小时”来给出建议,而Watson 在10分钟内完成了上述过程。
不过,尽管 Watson 的解决方案最快,但可能不是最好的。 NYGC临床医生识别了两个基因的突变,综合考虑,最后医生推荐患者参加了一项针对组合药物治疗的临床试验。如果患者的健康状况仍然允许,他将会参加这次试验,这本是他最有希望的生存机会。而Watson 没有以这种方式合成信息,因此没有给出临床试验的建议。
眼科疾病:中山大学和西安电子科技大学合作研发CC-Cruise,目前和医生表现相当
中国的一个研究团队已经论证,在有高质量数据可用的情况下,人工智能有可能帮助眼科疾病的医疗诊断。他们的AI 只训练了410张先天性白内障(一种导致不可逆失明的罕见疾病)的图像,再加上无病眼睛的476张图像,就能判断出白内障的严重程度,并提供治疗建议。
受到DeepMind 2015年研究报告的启发——该研究描述了基于最小激活信息的机器学习算法在一系列街机游戏中如何击败专业玩家——中山大学眼科医生HaotianLin 和同事们创建了一个AI智能体来挖掘他们的儿童期白内障临床数据库。
与西安电子科技大学的Xiyang Liu团队合作,他们创建了CC-Cruiser,一个能够诊断先天性白内障的AI程序,来预测疾病的严重程度,并给出治疗决策。该程序使用深度学习算法创建,用上述图像进行训练。
然后,研究人员对CC-Cruiser进行了五次测试。首先,在计算机模拟中,AI程序能够以98.87%的准确度区分患者和健康个体。估计疾病严重程度的三个指标中的每一个,——透镜不透明区域、密度和位置——准确率达到93%以上。该方案还提供了准确率达到97.56%的治疗建议。
接下来,该小组利用中国三家合作医院的57张儿童眼睛图像进行临床试验。所选择的医院都没有专门诊断或治疗这种病症的科室。因为该研究团队希望该平台最终将帮助缺乏专家的医院。测试中,CC-Cruiser表现良好:达到98.25%的识别精度;所有三个严重程度指标的判断准确率都超过92%,治疗建议准确率超过92.86%。
为了模拟现实世界的使用,他们将该程序和眼科医生的工作做了对比。三名眼科医师 - 一名专家、一名骨干和一名资历较浅的一声——和 CC-Cruiser 进行了50例临床病例的PK。计算机和医生表现相当。
在试验中,AI做出了几例不正确的标记,Lin 希望更大的数据集可以提高其性能。该团队计划建立一个协作云平台,但Lin强调,该技术“不够”以100%的准确度确定最佳治疗过程。因此,医生应该充分利用机器的建议来识别并防止潜在的错误分类,并作为自己判断的补充。
皮肤癌:自动皮肤癌分类最大数据集的构建
斯坦福大学的研究人员已经开发出一种算法,可以识别照片中的皮肤癌。它不是第一个识别皮肤病变的自动化系统,但可能是最强大的。
研究团队在GoogleNet Inception v3 架构上构建了一套深度学习算法,即一种卷积神经网络算法。斯坦福大学的研究人员对2000多种疾病近 13 万张皮肤病变图像进行了微调,这可能是自动皮肤癌分类中最大的数据集。
在研究中,该算法的结果与21名皮肤科医生的诊断进行了对比。医生检查了数百幅皮肤病变图像,并确定是否对其进行进一步检测,或者确保患者是良性的。该算法检测了相同的图像并给出了其诊断。医生和算法之前都没有看过图像。
最终结果,计算机与专家一致。例如,该程序能够区分角质形成细胞癌 - 最常见的人类皮肤癌- 和称为脂溢性角化病的良性皮肤生长。
在现实应用之前,斯坦福大学的系统将需要受到更严峻的考验。研究人员没有要求算法区分脂溢性角化病和黑素瘤,这可能是一个难点。
一般性诊断:大约72%的时间内,医生给出了正确的诊断。AI 则在 34%的时间里给出正确诊断
在 AI 和医生的 PK 中,医生们仍然有能够取胜的领域。此前发表的JAMA Internal Medicine上有一篇报告,指出一组自动诊断的 app 的诊断正确率远低于医生。
Mehrotra和他的团队2015年发表在BMJ(此前称为British Medical Journal)上的研究中,将45 名病人的症状投喂到23个症状检测系统中,其中包括随后被诊断患有哮喘和疟疾的患者。小组发现,三分之一以上的检测器给出了正确的诊断。
在新实验中,研究人员将检测器的准曲率和 234 名医师进行了比较。对于每种情况,至少有20名医生能够给出排名前三诊断的准确率。
大约72%的时间内,医生给出了正确的诊断。应用程序则在34%的时间里给出了正确的诊断。
“医生绝非完美,”Mehrotra说。“他们仍然可能在10%到15%的时间内诊断错误。然而,自我诊断app 想要超越医生,还需时日。”
原文地址:https://spectrum.ieee.org/static/ai-vs-doctors


数据库相关的软件
华为云-云数据库 RDS for MySQL
- 4.3
(2)咨询产品免费试用悦数图数据库
- 4.3
(4)咨询产品免费试用滴普科技
- 4.3
(44)咨询产品免费试用



行业专家共同推荐的软件
PostgreSQL
- 4.3
(42)咨询产品免费试用MySQL
- 4.0
(30)咨询产品免费试用Snowflake
- 4.0
(41)咨询产品免费试用



限时免费的数据库软件
Redis
- 4.1
(31)咨询产品免费试用Microsoft Access
- 4.1
(27)咨询产品免费试用Quickbase
- 4.0
(40)咨询产品免费试用



新锐产品推荐
灵猫SCRM
- 5.0
(1)咨询产品免费试用知店SCRM
- 0.0
(0)咨询产品免费试用凌风SCRM
- 0.0
(0)咨询产品免费试用派加-SCRM
- 0.0
(0)咨询产品免费试用企微魔盒
- 0.0
(0)咨询产品免费试用科汛SCRM
- 0.0
(0)咨询产品免费试用







