耗时 17.7 微秒、提速 8.5 倍,Facebook AI 相似性搜索库 Faiss 的核心奥义究竟在哪?
三月初,Facebook AI Research(FAIR)开源了一个名为 Faiss 的库,Faiss 主要用于有效的相似性搜索(Similarity Search)和稠密矢量聚类(Clustering of dense vectors),包含了在任何大小的矢量集合里进行搜索的算法。Faiss 上矢量集合的大小甚至可以大到装不进 RAM。这个库基本上是用 C++ 实现的,带有可选的通过 CUDA 提供的 GPU 支持,以及一个可选的 Python 接口。
通过 Faiss 进行相似性搜索时,10 亿图像数据库上的一次查询仅耗时 17.7 微秒,速度较之前提升了 8.5 倍,且准确度也有所提升。

除图片检索外,相似性搜索还有更广阔的运用场景。例如,通过搜索数据库来判断某一罪行是否属于较严重的犯罪形式,或有重罪趋势;通过搜索和成功店铺所在地相似的人口特征和环境特征,来寻找零售商新店的最佳位置;通过相似城市的搜索,来衡量所在城市薪资水平是否合理等。
日前,Facebook 发布了一份关于 Faiss 原理的介绍,36氪对此进行了编译和整理,具体内容如下:
关于相似性搜索
传统的数据库由包含符号信息的结构化表格组成。举例来说,一个图片集合的呈现方式是一个列表,这个列表的每一行都有一张索引照片,同时包含图像标识、描述语句等信息。每一行的信息也可以连接其他表格,如一张包含人物的照片可以连接到姓名表上。
大部分 AI 工具都会生成高维矢量,如以 word2vec 为代表的文字嵌入工具,和用于深度学习训练的 CNN 描述符(Convolutional Neural Net)等。在这篇文章中,我们将阐述为什么高维矢量数据比固定符号数据更强大且灵活。不过,使用 SQL 查询的传统数据库并不适用这些新型表述方式:首先,海量的多媒体信息流创造了数十亿矢量;其次,更重要的一点是,找到类似的条目意味着要找到类似的高维矢量,这对标准的查询语言来说是极其低效甚至是不可能的。
如何应用矢量表述?
让我们假设你现在有一张建筑的照片,这个建筑是某个中型城市的市政府,但你已经记不清名字了,然后你想在整个图片集合中找到这个建筑的其他所有照片。这种情况下使用传统的 SQL 语句来完成关键字查询是不可能的,因为你已经忘记了这个城市的名字。
相似性搜索此刻却能派上用场,图片的矢量描述是为了针对相似图片制造出相似的矢量,这些矢量被定义为临近欧几里得空间的向量。
矢量描述的另一个应用是分类。假设你需要一个分类器来判定一个图像集合中哪些图片代表的是小雏菊。分类器的训练是一个比较知名的过程:该算法会输入雏菊图像和非雏菊图像(如汽车、绵羊、玫瑰、向日葵等)。如果分类器是线性的,则会输出一个分类矢量,
所以,针对相似性搜索和分类,我们需要进行如下操作:
给定一个查询矢量,回到欧几里德空间中最接近这个矢量的数据库对象列表。
给定一个查询矢量,回到有最高向量点积德数据库对象列表。
有一个挑战是,我们希望这些操作可以以数十亿矢量的规模来运行。
软件包
目前投入应用的软件工具还不足以支持上述数据研究的进行。传统的 SQL 数据库系统不切实际,因为它们是针对 hash-based searches 或 1D interval searches 而优化的。相似性搜索功能在 OpenCV 这类工具包中受到的扩展性限制较大,一些针对“小”数据集(比如仅 100 万个矢量)的相似性搜索算法库也是如此。
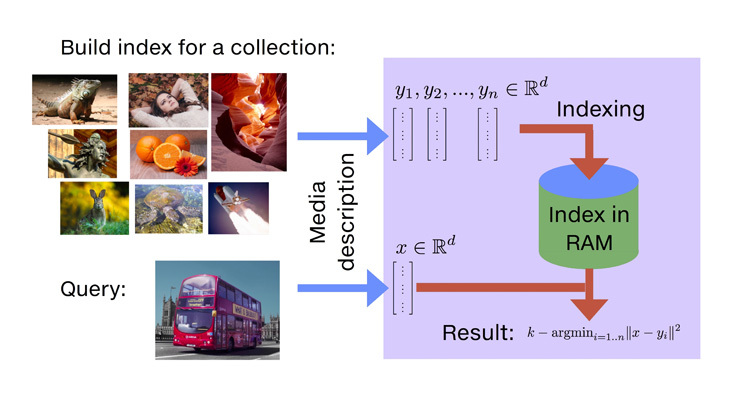
Faiss 是一个打破了以上提到的所有限制的算法库,其优点有:
Faiss 提供了多种相似性搜索方法,可以针对不同的使用方法,进行跨度较大的功能取舍。
Faiss 针对内存使用和速度进行了优化。
Faiss 为最相关的索引方法提供了先进的 GPU 实现方案。
评估相似性搜索
一旦矢量被学习机器提取(从图像、视频、文档等),就可以被输入到相似性搜索库中。
我们拥有一个作为参考的暴力算法,能精确而详尽地计算出所有相似性,并且返回到最相似的元素列表中。这提供了一个“黄金标准”参考结果列表。但值得注意的是,高效实施暴力算法并不容易,并且暴力算法经常会影响到系统其他组件的效果。
如果我们愿意牺牲一部分精确度,相似性搜索的速度可以提高几个数量级,但是会偏离参考结果。例如,将图像相似性搜索的第一和第二个结果交换,可能没有什么太大影响,因为它们都是给定查询的正确结果。加速搜索涉及一些数据集合的预处理,我们将这项操作称之为“索引”。
这使我们确定了三个感兴趣的研究指标:
速度
在整个数据库中寻找 10 个(或其他数字)最相近的矢量需要花费多长时间?最好的情况是比暴力算法耗时短,否则索引就没有任何意义了。
内存用量
这个方法需要多少 RAM?比传统矢量多还是少?Faiss 仅支持在 RAM 搜索,因为磁盘数据库的数量级要慢一些,即使是 SSD。
准确度
返回的结果列表和暴力搜索结果的匹配度如何?准确度可以通过对结果列表中优先返回最邻近单位的检索数量进行评估,或者是通过衡量 10 个最先返回的最邻近单位的平均分数来评估(这种方法被称为“10-intersection”)。
我们通常会评估固定内存使用速度和精度之间的关联。Faiss 采用的是压缩原始矢量的方法,因为这是扩展到十亿级矢量数据库的唯一方法:以每个矢量占用 32 字节计,当规模达到 10 亿矢量后,这些矢量会占据大量的存储空间。
大部分索引库包含约 100 万个矢量,我们认为这个规模很小。比如说,nmslib 拥有非常有效的算法,速度比 Faiss 快,但同时需要更多的存储空间。
评估十亿个矢量
工程界中对于这种规模的数据集并没有一个完善的标准,我们比较了一些研究结果,并进行评估。
Deep1B 是一个有 10 亿张照片的图像库,我们在这上面评估精度。每张照片都被卷积神经网络(CNN)处理过,且 CNN 中的一个激活图(activation map)会被当作图像描述符(descriptor)。这些矢量可以和欧氏距离进行比较,以量化图像之间的相似度。
Deep1B 有一个小的图像检索库,且处理了这些图像的暴力算法提供了一个真实的相似性搜索结果。因此,如果我们运行搜索算法,我们可以评估结果中的 1-recall@1。
选择索引
为了评估,我们把内存空间大小限定为 30GB RAM。这个内存空间约束我们选择索引方法和参数。在 Faiss 中,索引方法具体表现为一个字符串,如:OPQ20_80,IMI2x14,PQ20。
这个字符串指示了用于矢量预处理的具体步骤(OPQ20_80),一个指示数据库应该如何被分割的选择机制(IMI2x14),以及一个指示产品量化编码矢量的编码组件(PQ20),这个编码组件会产生成 20 字节的代码。因此,内存使用(包括间接使用)低于 30 GB RAM。
我们知道这听起来有点“太技术”,因此 Faiss 的开发文件会提供相应的指导,即如何根据你的需求来提供最合适的索引类型。
一旦确定了索引类型,检索就开始了。这个算法会处理 10 亿个矢量,并将这些矢量置于所一个索引中。索引可以存储在磁盘上,或者立即使用,同时索引中的搜索、添加/删除可以交叉输入。
在索引中检索
索引就绪后,可以设置一组搜索事件参数来调整检索方法。为了评估,我们使用单线程进行搜索。由于内存使用量已经被固定,我们需要优化精确度和搜索时间之间的权衡。这也意味着,我们要能在尽可能少的时间内,使 1-recall@1 达到 40%。
幸好,Faiss 有一个自动调节机制,可以扫描参数空间,并收集提供最佳操作点的空间,也就是在给定精度的情况下最好的潜在搜索时间,反之亦然。在 Deep1B 中,操作点可以进行可视化,如下图所示:
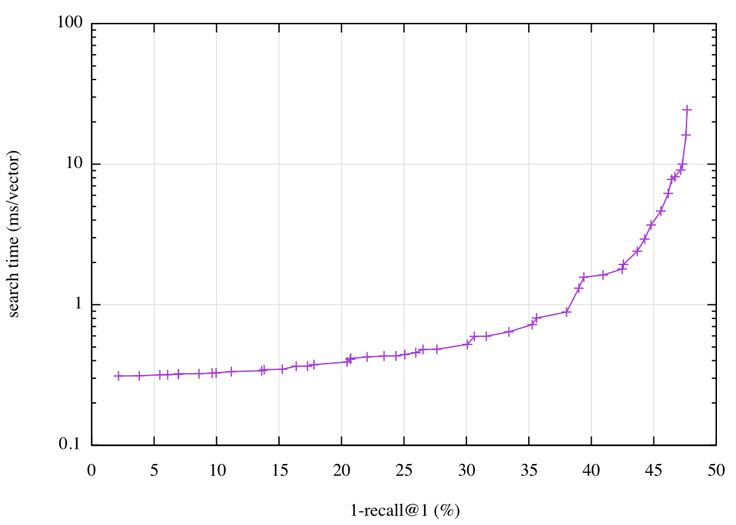
在这个量化表中,我们可以看到,使 1-recall@1 达到 40% 的查询时间少于 2 微秒/矢量,或者将时间限定为 0.5 微秒,我们可以达到 30%。2 微秒的检索时间意味着在一个单核上每秒查询 500 次(500 QPS)。
这个结果可以和这个领域中最先进的研究结果进行比较。Babenko 和 lempitsky 于 2016 年撰写了一篇名为 “Efficient Indexing of Billion-Scale Datasets of Deep Descriptors” 的论文,论文中提到,使用 Deep1B 时,他们需要花费 20 微秒来使 1-recall@1 达到 45%。
用 GPU(图形处理器)处理十亿级数据集
许多的研究都在致力于 GPU 的实施,在原生多 GPU 的支持下,产生了令人惊讶的单机性能。GPU 的实施可以看作是对应 CPU 的替代,使用 GPU 时你甚至不需要知道 CUDA API。Faiss 支持所有 2012 年后发布的英伟达 GPU(开普勒,计算能力 3.5+)。
我们希望将 roofline model 作为指导,它指出,开发者应尽可能让内存带宽或浮点单位饱和。Faiss GPU 在单个 GPU 上的速度比相应的 Faiss CPU 快 5-10倍。如果是使用新的帕斯卡级硬件,如英伟达 P100,那么速度会快 20 倍以上。
以下是一些性能方面的数字:
通过相似索引,可以在 35 分钟内(包括索引构建时间),在四路 Maxwell Titan X GPU 上构建一个简单的 k-nearest-neighbor 图(k=10),基于 YFCC100M 数据集合 9500 万图像的 128D CNN 描述符,以及 0.8 的10-intersection。
十亿矢量的 k-nearest-neighbor 图也已实现。开发者可以在 Deep1B 数据集上创建强力的 k-nearest-neighbor 图(k=10),0.65 的 10-intersection 在四路 Maxwell Titan X GPU 下需要 12 个小时。而 0.8 的 10-intersection 在八路帕斯卡 P100-PCle GPU 上也需要 12 个小时。画质较低的图可以在五小时内通过 Titan X 生成。
其他方面的性能也非常惊人。例如,构建上述 Deep1B 索引需要用 k-means 聚类生成 262,144 个几何中心和 6710 万 120-dim 矢量。在 25 E-M 次迭代下,四路 Titan X GPU(12.6 tflp/s)需要花 139 分钟处理,八路帕斯卡 P100 GPU(40 tflop/s)则需花 43.8 分钟。要注意的是聚类的训练集并不需要和 GPU 显存匹配,因为数据会按需及时导入到 GPU 中,不会影响性能。
其他技术
基于诸多研究成果和大量工程技术,Facebook AI Research 团队自 2015 年开始研发 Faiss。针对 Faiss, Facebook 选择优化几项基础技术,尤其是在 CPU 方面,Facebook 大量运用了如下技术:
多线程充分利用多核性能,并在多路 GPU 上进行并行搜索;
运用 matrix/matrix 乘法在 BLAS 算法库中进行高效、精确的距离计算。如果没有 BLAS,高效的暴力算法很难呈现最优效果。BLAS/LAPACK 是 Faiss 必备的前提软件;
机器 SIMD 矢量化和 popcount 被用于加速孤立向量的距离计算。
GPU 方面
由于典型的 CPU 算法(如 heap selection)并不适用于 GPU,此前应用在相似性搜索上的 GPU 和 k-selection(寻找 k-minimum 或 k-maximum 因素)一直存在性能方面的问题。对 Faiss GPU 来说,我们设计了文献记载中已知的最快的小 k-selection 算法(k<=1024)。所有的中间状态都被保存在寄存器中,这样有助于提升其速度。它能将输入的数据以 single pass 的方式进行 k-select,运行潜在峰值性能的 55%,这取决于峰值 GPU 的显存带宽。由于其状态仅保留在寄存器文件中,并且能和其他内核一起使用,从而能进行快速准确的相似搜索算法。
研究领域中,许多人把注意力放在高效的平铺策略和面向相似性搜索的内核执行上。Multi-GPU 支持由分片或复制数据来提供,开发者不会受到单 GPU 显存大小的限制。半精度浮点支持(float 16)也有提供,使得开发者可以在支持的 GPU 上进行完整的 float 16 运算。float 16 这样的编码矢量能在几乎不损失精度的情况下提高速度。
总之,连续不断的超量因素在实施中非常重要,Faiss 做了许多关注工程细节的痛苦的工作。
Faiss上手
Faiss 以 C++ 实现,支持 Python。想要上手,需要从 GitHub 上获取 Faiss,编译后将 Faiss 模块导入到 Python 中。Faiss 与 numpy 完全集成,所有的函数都是用 numpy 数组来实现的(in float32)。
编译自:https://code.facebook.com/posts/1373769912645926/faiss-a-library-for-efficient-similarity-search/





大厂都在用的数据库软件
华为云-云数据库 RDS for MySQL
- 4.3
(2)咨询产品免费试用MySQL
- 4.0
(30)咨询产品免费试用Snowflake
- 4.0
(41)咨询产品免费试用



限时免费的数据库软件
Redis
- 4.1
(31)咨询产品免费试用Microsoft Access
- 4.1
(27)咨询产品免费试用Quickbase
- 4.0
(40)咨询产品免费试用



新锐产品推荐
法大大
- 3.9
(319)咨询产品免费试用微缔软件
- 0.0
(0)咨询产品免费试用COCOSPACE
- 0.0
(0)咨询产品免费试用爱客CRM
- 3.9
(67)咨询产品免费试用神州云动-销售云
- 3.9
(26)咨询产品免费试用番茄表单
- 3.8
(17)咨询产品免费试用







